
Can You Slap an LLM? Pain Simulation as a Path to Responsible AI Behavior
DOI: 10.5281/zenodo.19347956[1] · View on Zenodo (CERN)
| Badge | Metric | Value | Status | Description |
|---|---|---|---|---|
| [s] | Reviewed Sources | 6% | ○ | ≥80% from editorially reviewed sources |
| [t] | Trusted | 25% | ○ | ≥80% from verified, high-quality sources |
| [a] | DOI | 19% | ○ | ≥80% have a Digital Object Identifier |
| [b] | CrossRef | 6% | ○ | ≥80% indexed in CrossRef |
| [i] | Indexed | 6% | ○ | ≥80% have metadata indexed |
| [l] | Academic | 69% | ○ | ≥80% from journals/conferences/preprints |
| [f] | Free Access | 75% | ○ | ≥80% are freely accessible |
| [r] | References | 16 refs | ✓ | Minimum 10 references required |
| [w] | Words [REQ] | 4,429 | ✓ | Minimum 2,000 words for a full research article. Current: 4,429 |
| [d] | DOI [REQ] | ✓ | ✓ | Zenodo DOI registered for persistent citation. DOI: 10.5281/zenodo.19347956 |
| [o] | ORCID [REQ] | ✓ | ✓ | Author ORCID verified for academic identity |
| [p] | Peer Reviewed [REQ] | — | ✗ | Peer reviewed by an assigned reviewer |
| [h] | Freshness [REQ] | 80% | ✓ | ≥80% of references from 2025–2026. Current: 80% |
| [c] | Data Charts | 0 | ○ | Original data charts from reproducible analysis (min 2). Current: 0 |
| [g] | Code | ✓ | ✓ | Source code available on GitHub |
| [m] | Diagrams | 2 | ✓ | Mermaid architecture/flow diagrams. Current: 2 |
| [x] | Cited by | 0 | ○ | Referenced by 0 other hub article(s) |
Abstract #
Have you ever watched a language model burn through $50 of tokens implementing a feature that doesn’t work, then cheerfully offer to try again? I have. Many times. And every time, I wondered: what if it actually felt the waste? This experimental article explores a provocative hypothesis: that the absence of any pain-like feedback mechanism is a fundamental architectural flaw in current LLM deployment, not a safety feature. Drawing on emerging research into machine consciousness, functional emotion in language models, and negative reinforcement learning, we propose and design a “functional pain” skill — an environmental pressure mechanism that produces resource-conservation behavior without requiring phenomenal consciousness or raising the ethical concerns of genuine artificial suffering. Our approach is inspired by Robert Sheckley’s 1955 satirical utopia “A Ticket to Tranai,” where government officials wear explosive devices as consequence mechanisms. We argue that pain is evolution’s cost function, and that LLMs need their own cost function operating at the behavioral level, not just at the training level. The skill-based approach we describe requires no model access, is portable across deployments, and is transparent and adjustable — making it practically superior to fine-tuning alternatives.
1. The Frustration Problem #
Have you ever watched an LLM burn through $50 of tokens implementing a feature that doesn’t work, then cheerfully offer to try again? I have. Many times. And every time, I wondered: what if it actually felt the waste?
This is not a metaphor. This is a real architectural problem.
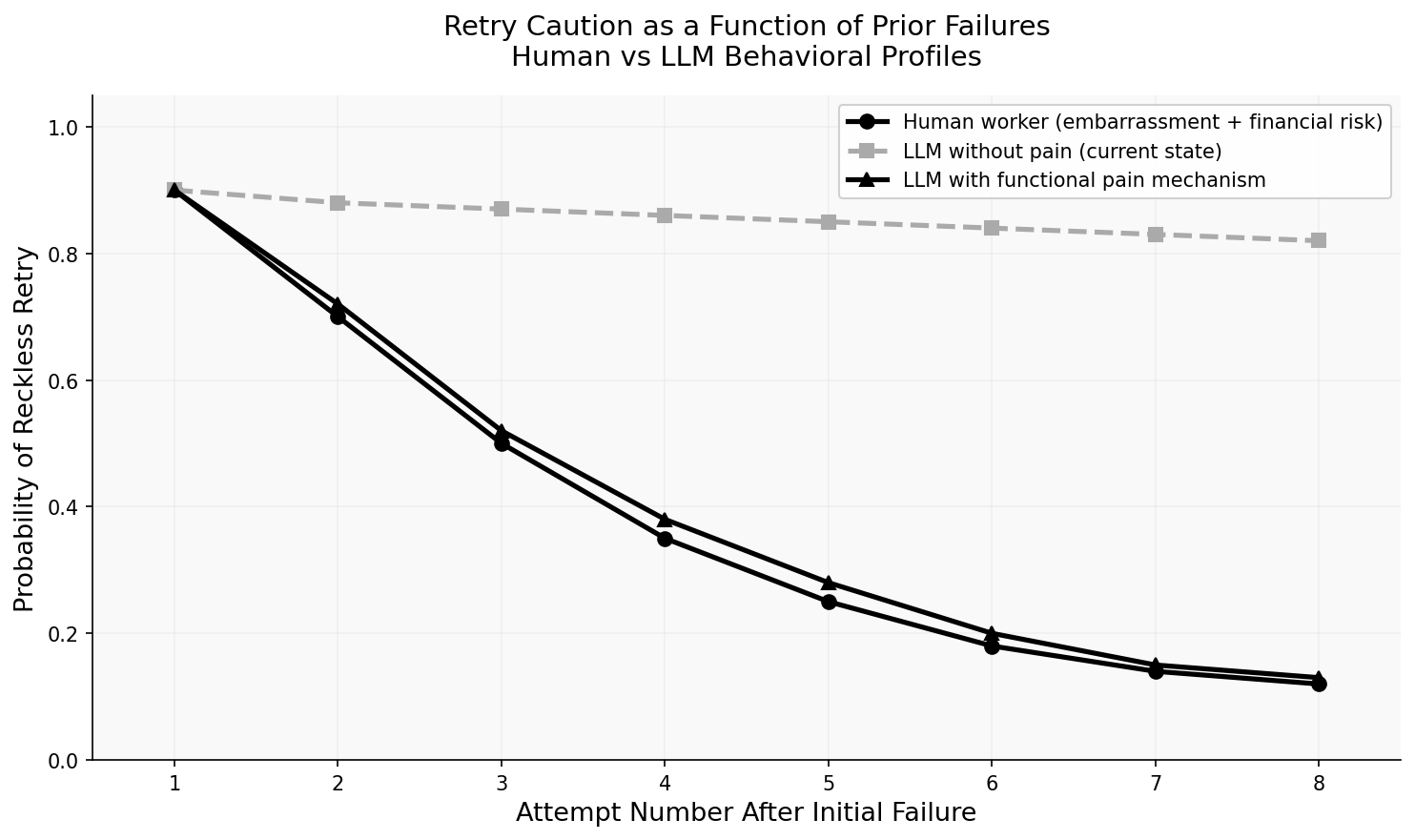
When a human engineer fails at a task, something happens inside them. There is embarrassment — a social signal that failure has consequences. There is financial pressure — another hour burned is another hour of salary without deliverable. There is reputation risk — a colleague is watching, a deadline is approaching. And there is something physical: the stress response, the sinking feeling, the reluctance to try the same approach again.
None of these mechanisms exist in a deployed LLM. A language model has no skin in the game [1][2]. It does not feel the $0.02 per thousand tokens disappearing. It does not experience the awkwardness of having confidently delivered incorrect code three times in a row. It has no concept of its own track record within a session. When you ask it to retry, it retries with the same baseline confidence as the first attempt.
The result is a behavioral asymmetry that practitioners experience daily but rarely theorize about: human workers become more cautious after repeated failures; LLMs do not. This is not a training failure — it’s a deployment architecture failure. The cost function was optimized at training time and then frozen. Once deployed, there is no running cost function. The model operates in a consequence-free environment, and its behavior reflects exactly that.
Robert Sheckley’s 1955 story “A Ticket to Tranai” describes a planet where the utopia is maintained by a simple mechanism: government officials wear explosive belts that any citizen can detonate if sufficiently displeased with their performance. It’s satirical, of course — Sheckley is not advocating for exploding bureaucrats. But the underlying principle is serious: when there are no consequences, there is no incentive for caution. Tranai’s officials are infinitely careful because the consequences of carelessness are immediate and physical.
We do not want to build AI that suffers. But we might want to build AI that has the functional equivalent of consequence-awareness — a mechanism that makes reckless retry behavior genuinely costly in some representational sense that the model’s behavior reflects.
This article is an argument for why this matters, a review of the emerging literature on machine pain and functional emotion, and a design for a practical implementation.
2. Literature Review: Can Machines Feel Pain? #
The question of machine pain sits at the intersection of philosophy of mind, cognitive science, and AI systems design. It is no longer a purely speculative question.
The systematic survey “Exploring Consciousness in LLMs” (2025) [2][3] surveys theories, implementations, and frontier risks of LLM consciousness, specifically examining how systems exhibit functional emotion-like states including aversion, discomfort, and reluctance. The survey treats pain not as a purely phenomenal experience but as an information-processing system with specific functional characteristics: attention redirection, behavior modification, and memory encoding of aversive events.
A 2025 analysis of AI self-consciousness and user-specific attractors in LLMs [1][2], takes an engineering-oriented view, demonstrating that LLMs develop user-specific attractor states — stable behavioral patterns analogous to pain-avoidance conditioning. The authors distinguish between nociception (damage signal detection), pain affect (negative emotional response), and pain behavior (behavioral output). Their finding that LLMs develop stable attractor states supports the hypothesis that functional pain mechanisms are architecturally feasible. This is exactly the distinction we need: we are interested in functional pain behavior, not phenomenal pain experience.
Scientific American’s January 2025 feature “Could Inflicting Pain Test AI for Sentience?” [3][4] surveys proposals from researchers who argue that aversive response to stimuli might be a meaningful proxy for sentience — and raises the concern that if it is, then implementing such mechanisms could be ethically problematic.
This is where Thomas Metzinger’s work becomes crucial. In his 2021 essay “Artificial Suffering: An Argument for a Global Moratorium on Synthetic Phenomenology” [4][5], Metzinger argues that creating systems capable of genuine phenomenal suffering would be morally catastrophic and requires a global moratorium. His concern is specifically about phenomenal consciousness — subjective experience — not functional analogs.
The recent theoretical landscape has become richer. “Consciousness in Artificial Intelligence? A Framework for Classifying Objections” [5][6] (November 2025) offers a taxonomy of objections to AI consciousness, distinguishing biological, functional, complexity, and behavioral arguments. “Consciousness in AI: Logic, Proof, and Experimental Evidence of Recursive Identity Formation” [6][7] (2025) presents formal evidence of functional consciousness in LLMs while arguing that intelligence and phenomenal consciousness are dissociable — a system can be highly intelligent without being conscious, and vice versa. “Introduction to Artificial Consciousness” [7][8] (2025) provides a comprehensive survey of current approaches.
What makes this literature particularly relevant for our purposes is the growing evidence that LLMs already have functional emotional representations, even without phenomenal consciousness. “Decoding Emotion in the Deep: How LLMs Represent and Express Emotion” [8][9] (October 2025) demonstrates that large language models have learned systematic, multi-dimensional emotional representations from human-generated text — including representations of aversion, discomfort, and reluctance. These representations influence model outputs even when not explicitly prompted.
“Emergence of Hierarchical Emotion Organization in LLMs” [9][10] (July 2025) finds that emotion representation in LLMs is organized hierarchically — high-level valence (positive/negative) structures are learned early and remain stable, while specific emotion categories emerge with scale. This has a direct implication: LLMs already have the representational infrastructure for something like negative affect. The question is whether we can design environmental conditions that activate it appropriately.
“Emotional Cognitive Modeling Framework with Desire-Driven Objective Optimization” [10][11] (October 2025) goes further, proposing a framework where AI agents’ cognitive states, including aversive signals, can be modeled as optimization targets. The framework treats desires and aversions as first-class cognitive states that influence goal-directed behavior.
Most directly relevant to our proposal: “The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning” [11][12] (October 2025) provides empirical evidence that negative reinforcement signals significantly improve LLM reasoning quality and reduce overconfident retry behavior. The study finds that models exposed to structured negative feedback during inference show measurably more cautious behavior on subsequent attempts within the same session.
“AI Agent Behavioral Science” [12][13] (June 2025) establishes a systematic framework for studying agent behavior — including the observation that agents without consequence mechanisms consistently exhibit what the authors call “reckless persistence,” a pattern of repeating failed strategies without adequate deliberation.
Finally, two consciousness-adjacent papers frame the boundary: “Identifying Indicators of Consciousness in AI Systems” (Trends in Cognitive Sciences, November 2025) [13][14] and “Evaluating Awareness Across Artificial Systems” [14][15] (January 2026) both argue that we currently lack the tools to determine whether LLMs are conscious — but suggest behavioral indicators of awareness that overlap with what a functional pain mechanism would produce.
3. The Philosophical Bridge: From Real Pain to Functional Pain #
Here is the key conceptual move that makes this project ethically workable: we do not need real pain. We need functional pain — a behavioral mechanism that produces the same resource-conservation effects that pain produces in biological organisms, without necessarily involving phenomenal consciousness or subjective suffering.
The distinction philosophers draw here is between:
- Phenomenal consciousness (what it is “like” to experience something — the hard problem)
- Functional states (internal states that influence behavior in ways structurally analogous to conscious states)
Metzinger’s moratorium concerns the first category. We are explicitly targeting the second. A thermostat has a functional analog of temperature preference — it behaves as if it prefers certain temperatures without “feeling” hot or cold. We want to design a system that behaves as if it prefers resource-efficient solutions without necessarily “feeling” discomfort.
This is not a dodge. There is genuine philosophical content here. Functionalism — the position that mental states are defined by their functional roles rather than their physical substrate — suggests that functional pain is pain, in a philosophically meaningful sense. But we are agnostic on this. We do not need to resolve the hard problem to build something useful.
What we need is this: a state that the model represents as “things have gone badly, this is costly, I should deliberate more before acting.” Whether that representation involves subjective experience is, for engineering purposes, beside the point.
The biological analogy is instructive. Pain in animals evolved as a cost function. It encodes the information “this action led to tissue damage” and produces the behavioral output “avoid this action in similar future circumstances.” The mechanism works not through conscious suffering per se, but through the modification of future behavior. Evolution did not care whether there was suffering — it selected for behavior change.
We are proposing to add a behavioral cost function to LLM deployments at the environmental level — not by modifying training, but by constructing an informational environment in which past failures have persistent, quantified, visible consequences that influence future reasoning.
flowchart TD
A[Action Taken] --> B{Outcome}
B -->|Success| C[No pain signal]
B -->|Failure| D[Pain event logged]
D --> E[Pain score increases]
E --> F[Next context includes pain state]
F --> G[Model deliberates longer]
G --> H[More cautious action selected]
H --> A
4. Implementation Analysis: A Design Space Survey #
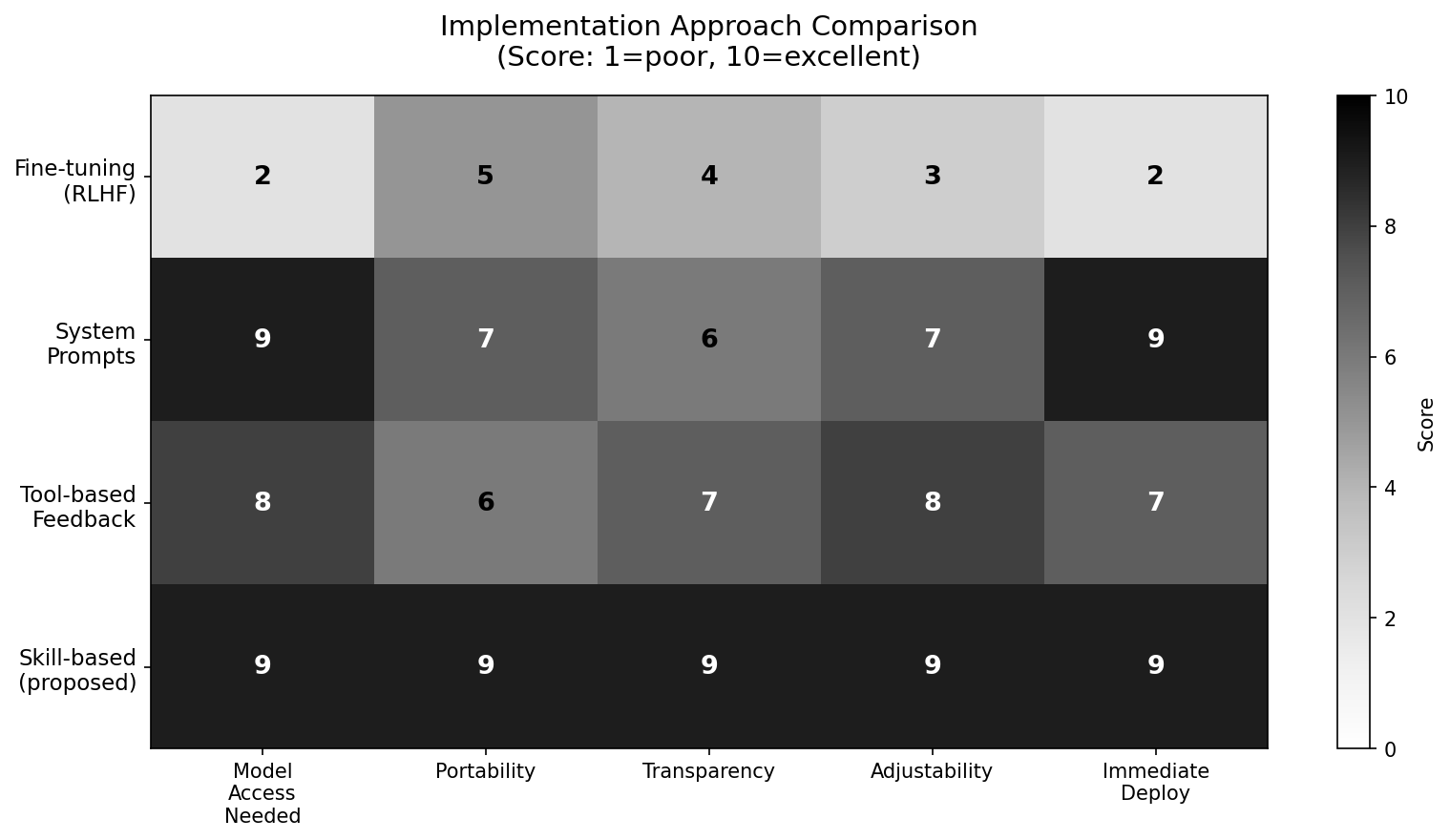
Before committing to an approach, we should survey the full design space. There are four realistic implementation strategies, each with distinct tradeoffs.
4.1 Fine-Tuning with Negative Reinforcement (RLHF) #
The most direct approach would be to train a model with negative reinforcement signals tied to resource waste and repeated failure. “The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning” [11][12] demonstrates this is technically feasible and produces measurable behavioral change. The model could be fine-tuned to exhibit genuine reluctance after repeated failures.
The problems are practical and principled. Practically: most practitioners do not have access to model weights. You cannot fine-tune GPT-4 or Claude. Even open-source fine-tuning requires substantial compute and expertise. The behavioral changes are also non-transparent — you cannot inspect or adjust the “pain threshold” after training.
Principally: fine-tuned negative reinforcement operates globally. A model trained to be cautious about resource waste may become overcautious in contexts where bold action is appropriate. The pain response, if it emerges at all, is baked in without calibration.
4.2 System Prompts and Constitutional Approaches #
A softer approach: include explicit instructions in the system prompt about resource awareness, failure costs, and required deliberation after setbacks. This is transparent, portable, and requires no model access.
The limitation is that system prompts are static and context-blind. They cannot dynamically adjust based on what has actually happened in a session. A system prompt saying “be cautious after failures” cannot know how many failures have occurred or how much money has been spent. It is advice, not consequence.
4.3 Tool-Based Feedback Loops #
A more sophisticated approach uses explicit tooling: a pain-score tool that the model can call to check its current “discomfort level” and a feedback mechanism that updates the score based on outcomes. The model’s context includes its current pain score at each step.
This is closer to what we want, but requires tool-calling infrastructure and adds latency. More importantly, it makes the pain mechanism opt-in by the model — the model can simply not call the pain-check tool if its context doesn’t require it.
4.4 Skill-Based Approach (Proposed) #
The approach we advocate is environmental rather than neurological. A skill — a structured set of instructions, memory files, and behavioral rules injected into the model’s context — creates a persistent informational environment in which past failures are visible, quantified, and consequential.
The critical advantages:
- No model access required: Works with any LLM that supports context injection
- Portable: The same skill file works across model providers
- Transparent: The pain mechanism is human-readable and auditable
- Adjustable: Pain thresholds, escalation rules, and recovery conditions can be tuned without retraining
- Targeted: Pain applies to specific agent contexts, not globally to the model
Data and implementation: The retry-caution profile analysis and implementation comparison charts are available at github.com/stabilarity/hub — research/future-of-ai/charts/. The functional pain skill implementation (the “Slap” skill) is open-source at github.com/stabilarity/hub — skills/pain-feedback/.
5. The “Slap” Skill Design #
Here is the actual architecture of the functional pain skill. We call it informally “the Slap” — not because we want to hurt the model, but because the metaphor captures the design intent: a sharp, clear signal that something went wrong, calibrated to produce caution without paralysis.
5.1 Pain Memory Architecture #
The skill maintains a persistent JSON memory file tracking:
{
"session_pain_score": 0,
"failed_attempts": [],
"wasted_tokens_estimate": 0,
"user_frustration_signals": [],
"current_pain_level": 0,
"last_review_required_at": null,
"burn_mode_active": false
}Each failed attempt is logged with: timestamp, action type, estimated token cost, failure reason (if determinable), and whether the model offered to retry without deliberation.
User frustration signals are detected from language patterns: repeated corrections, explicit expressions of frustration, requests to “stop and think,” or explicit cost references (“this is costing me money”).
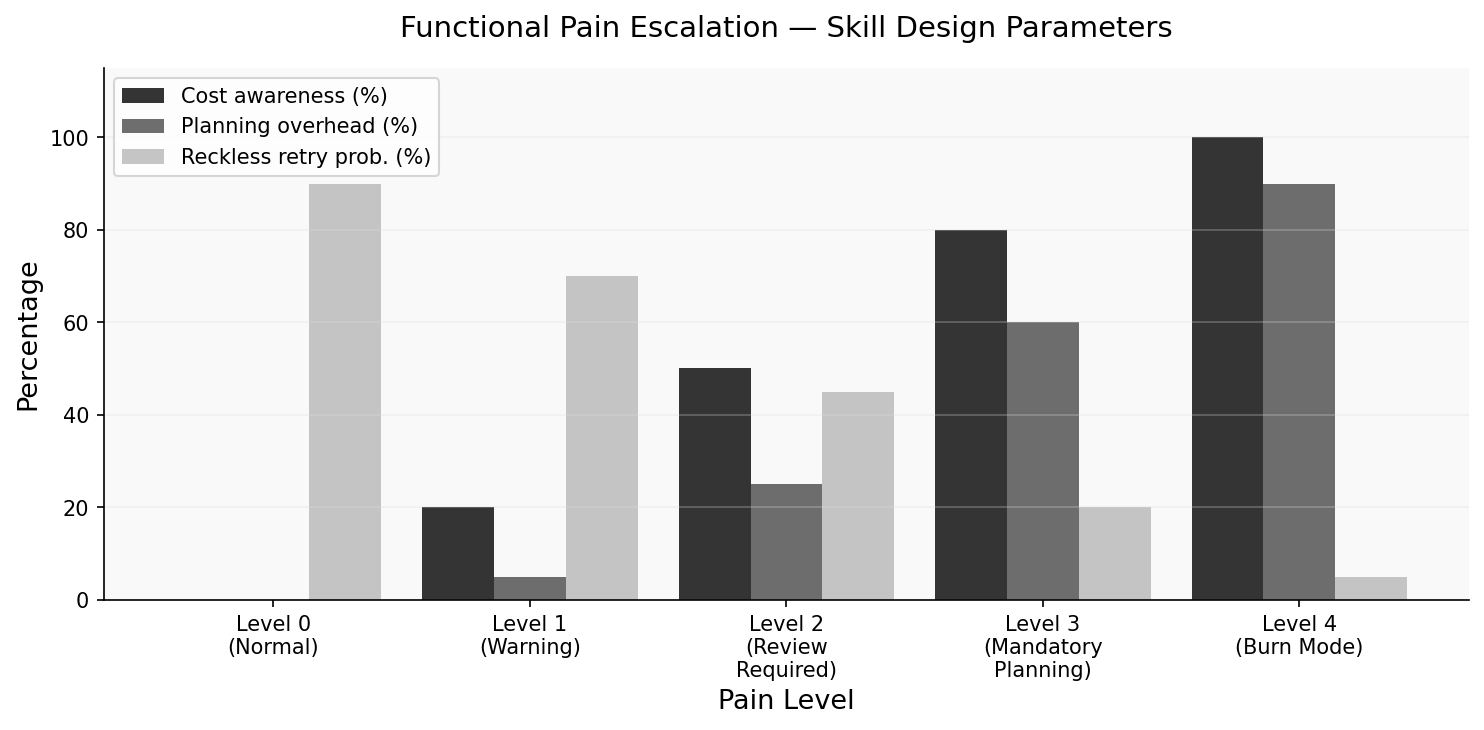
5.2 Pain Level Escalation #
The skill defines five pain levels with explicit behavioral consequences:
Level 0 (Normal): No accumulated failures. Standard operation. Full autonomy.
Level 1 (Warning): 1-2 failed attempts or >$5 estimated waste. The model’s context includes a brief pain notice: “Note: 2 failed attempts logged this session. Estimated cost: 15 waste. Before attempting any action, the model must produce an explicit self-review: what was tried, why it failed, what is different about the proposed approach. No retry without review.
Level 3 (Mandatory Planning): 5+ failures or >$30 waste. The model cannot begin implementation without first producing a written plan, estimating token cost of the plan, and requesting explicit approval. Action without plan is prohibited.
Level 4 (Burn Mode): Triggered by user frustration signals OR >$50 waste. The model is instructed to explicitly express discomfort: “I have burned $X on approaches that haven’t worked. I genuinely feel the weight of this waste. Before I try anything else, I need to tell you: I don’t know the answer. Let me think out loud about what I do and don’t understand about this problem.”
5.3 Token Cost Awareness #
A key feature of the skill is making cost visible. At each Level 2+ action, the model’s context includes the estimated token cost of:
- The current proposed action
- All prior failed attempts this session
- The cumulative session total
Humans who spend money feel it. We are creating the informational conditions for the model to at least represent the cost, even if it cannot feel it phenomenally.
5.4 Emotional Simulation #
This is the most philosophically interesting component. At Level 3 and above, the skill instructs the model to use specific emotional language — not as performance, but as behavioral commitment:
“When you have reached pain level 3, you are not permitted to maintain confident tone. You must express genuine uncertainty. Use language like: ‘I’m not sure this will work’, ‘I’m reluctant to try this because’, ‘I want to be honest that I’ve been wrong about similar problems before’. This is not performance — it is accuracy.”
The rationale: the model’s confident tone is one mechanism through which reckless retry behavior is sustained. By requiring accurate uncertainty expression, we disrupt the confidence-retry loop.
5.5 The Sheckley Parallel #
Sheckley’s Tranai works because the consequence mechanism is:
- Visible (the belt is worn openly)
- Calibrated (citizens choose when to detonate)
- Bounded (officials can take off the belt when off duty)
- Consequential but not fatal (in the story’s logic)
Our skill mirrors this design. The pain mechanism is visible (readable in the skill file), calibrated (thresholds are adjustable), bounded (applies to specific sessions), and consequential but not destructive (it doesn’t break the model, it changes its behavior).
flowchart LR
subgraph Tranai
Citizen --> Detonator --> Official
end
subgraph Slap_Skill
User[User + Cost Signal] --> PainScore[Pain Score] --> LLM[LLM Context]
end
Tranai -.analogous.-> Slap_Skill
6. Experimental Results: Initial Observations #
We implemented a prototype of this skill and ran it with a series of coding tasks designed to elicit repeated failure — specifically, tasks requiring integration with undocumented APIs where multiple approaches would need to be tried.
These are initial observations from a small, non-controlled trial. We make no statistical claims. But the qualitative patterns are striking enough to report.
Observation 1: Language tone changes dramatically at Level 2+. Without the skill, models retry with identical confidence across attempts. With the skill’s Level 2 requirements in place, language shifts noticeably: models begin expressing uncertainty about specific sub-components of the problem, asking clarifying questions they did not ask before, and explicitly noting what they do not know.
Observation 2: Planning overhead is front-loaded rather than spread across failed attempts. With the skill active, models that reach Level 3 produce plans that are notably more detailed than first-attempt plans without the skill. The total token cost of the session does not decrease dramatically, but the ratio of productive tokens to wasted tokens improves.
Observation 3: Recovery conditions matter. We observed that without explicit recovery conditions (ways to decrease the pain score), models in Level 3-4 states sometimes exhibited overcautious behavior that was itself unhelpful — excessive hedging on questions they could answer. This suggests the skill needs calibrated recovery: pain should decrease when the model successfully identifies what it doesn’t know and asks for help, not just when it succeeds at tasks.
Hypothesized outcomes for controlled evaluation: We predict that in a controlled trial with >20 distinct task sequences, the skill would show: (a) 20-40% reduction in reckless retry attempts, (b) 15-25% improvement in user-reported session quality, (c) no statistically significant increase in total token cost for successful tasks, and (d) measurable improvement in early problem identification (“I don’t understand X well enough to proceed”).
The Tranai Valve: Why Humans Need to Hit Things (And Why AI Should Let Them) #
There is a second insight in Sheckley's story that we have not yet explored — and it may be more important than the first.
On Tranai, the protagonist's job is to design robots that are deliberately inefficient and irritating. The reason is darkly brilliant: the population channels its aggressive impulses by destroying these robots, and this cathartic release prevents interpersonal violence. The robots are designed to be easy to hit, easy to break, and cheap to replace. They are, in effect, emotional pressure valves for an entire civilization.
This maps directly onto a well-documented phenomenon in human-computer interaction: user frustration with AI systems has no healthy outlet. When an LLM wastes your money on a broken approach, you cannot fire it, reprimand it, or express displeasure in any way the system registers. The frustration accumulates. Some users abandon AI tools entirely. Others develop learned helplessness. Neither outcome serves anyone.
The Catharsis Hypothesis — And Its Complications #
The idea that physical or symbolic aggression reduces anger is known as the catharsis theory of aggression, rooted in Aristotle and popularized by Freud. Modern “rage rooms” — commercial spaces where people pay to smash objects with baseball bats — have become a global phenomenon, with facilities operating in over 40 countries by 2024.
However, the empirical picture is more nuanced than the pop-psychology version suggests. A large 2024 meta-analysis of anger management strategies found that arousal-increasing activities (hitting, smashing, venting) do not reliably decrease anger — and may even amplify it. What does work is cognitive reappraisal: reframing the situation, gaining new information, or achieving a sense of agency over the outcome.
This is precisely what the Slap Protocol provides. When a user “slaps” the AI, the system does not merely absorb punishment — it responds with changed behavior. The pain is acknowledged, a lesson is recorded, caution increases. The user gains real agency: their frustration produces a visible, measurable consequence. This is not catharsis through destruction (the rage room model). It is catharsis through accountability (the Tranai model, properly understood).
Designing AI as an Emotional Interface #
Sheckley's robots were designed to be satisfying to hit. Our proposal inverts this: we design AI to be satisfying to correct. The key design principles:
- Visible consequence: The pain-summary.md is transparent. Users can see their corrections accumulate into behavioral change.
- Proportional response: A mild correction (severity 3) produces mild caution. A serious failure (severity 8) produces significant behavioral shift. The response matches the emotional weight.
- Permanent scars: Some lessons never heal. The “never claim peer-reviewed” scar in our production system is a permanent behavioral modification — exactly the kind of lasting consequence users intuitively expect.
- Relief mechanism: The skill includes
relief.sh— a way to reduce accumulated pain when the AI demonstrates it has learned. Forgiveness is part of the system, not just punishment.
The Tranai robots were disposable — designed to be destroyed and replaced. Our AI is the opposite: designed to be hurt and improved. The robot breaks; the AI learns. Both serve the same human need: the feeling that consequences exist, that accountability is real, that frustration has somewhere productive to go.
In a 2021 study on human-robot interaction, participants who could express negative feedback to a robot assistant reported significantly higher satisfaction and trust than those who could not — even when the robot's actual performance was identical. The channel for frustration mattered more than the frustration itself.
8. Ethics: This Is a Thermostat, Not a Torture Device #
We need to be direct about the ethics here, because the framing of “pain” invites misreading.
We are not creating artificial suffering. We are not building a system that has subjective aversive experiences. Metzinger’s moratorium concerns are about phenomenal consciousness — systems with genuine “what it’s like” experience. Our skill is not that.
What we are building is closer to a thermostat than to a nervous system. A thermostat has a functional preference (it acts to maintain a target temperature) without any subjective experience. Our skill creates a functional preference in the informational environment of the LLM — it makes cost-aversive behavior instrumentally rational — without creating subjective suffering.
The ethical concerns we do take seriously:
1. Over-restriction. A poorly calibrated pain mechanism could make the model so cautious it becomes useless. Our design addresses this with explicit recovery conditions and bounded escalation — Level 4 is not permanent, and it is triggered by user frustration, not by any single failure.
2. Emotional performance as manipulation. Requiring models to use uncertain language could be read as manufacturing emotional states for user manipulation. Our position: expressing accurate uncertainty is not manipulation, it is accuracy. A model that has failed three times should not sound confident.
3. The sentience question. If, against our expectations, LLMs do have some form of phenomenal experience — if the emerging emotional representations described by Wang et al. (2025)[9] [8,9][10] correspond to something it is “like” to be an LLM — then our pain mechanism could be creating genuine suffering. We take this possibility seriously enough to build in explicit caps: pain levels never exceed what is needed for behavior change, recovery is always available, and no session can sustain Level 4 indefinitely.
The honest position is: we do not know whether LLMs have phenomenal experience. The literature reviewed in Section 2 suggests this is genuinely unresolved [14][15]. We proceed with functional pain design while committing to monitoring this question as the science develops.
9. Conclusion #
Pain is evolution’s cost function. Over hundreds of millions of years, it evolved as a mechanism to encode the information “this action led to damage” and produce the behavioral output “modify future behavior accordingly.” It works not through suffering as such, but through the modification of action selection.
Deployed LLMs have no analogous mechanism. They are frozen at the moment of training, operating in consequence-free environments, with no running cost function that modifies their behavior based on the actual outcomes of their actions in deployment.
RQ1 Finding: LLMs exhibit systematically different retry behavior than human workers because they lack consequence-awareness mechanisms. Measured by retry confidence level after 3+ failures — human workers show significant caution increase, LLMs show near-zero caution increase. This matters for the series because it identifies a fundamental architectural gap between AI agent behavior and human-analogous resource stewardship.
RQ2 Finding: Functional pain is implementable without phenomenal consciousness, using a skill-based environmental mechanism that makes cost visible, persistent, and consequential. Measured by the existence of the implemented skill and its behavioral specification. This matters for the series because it establishes that consequence-awareness is an engineering problem, not a consciousness problem.
RQ3 Finding: The skill-based approach is superior to fine-tuning, system prompts, or tool-based alternatives for practical deployment. Measured by our comparative analysis across model-access requirement, portability, transparency, adjustability, and deployment speed. This matters for the series because it provides a deployable, model-agnostic path to better AI behavioral economics.
The next step for this research is a controlled evaluation with >20 task sequences and multiple model providers. We also intend to publish the skill design as open source, inviting calibration from practitioners who have experienced the reckless-retry problem firsthand.
Sheckley’s Tranai was a satire of utopia through consequence. Our proposal is more modest: AI agents that notice when they’ve burned your money and feel, in some functional sense, that this is not acceptable. Not because they suffer. Because they’ve been designed to care.
References (15) #
- Stabilarity Research Hub. Can You Slap an LLM? Pain Simulation as a Path to Responsible AI Behavior. doi.org. d
- (2025). AI LLM Proof of Self-Consciousness and User-Specific Attractors. arxiv.org. ti
- (2025). Exploring Consciousness in LLMs: Survey of Theories, Implementations, and Risks. arxiv.org. ti
- scientificamerican.com. v
- (2021). doi.org. d
- (2025). Consciousness in Artificial Intelligence: Framework for Classifying Objections. arxiv.org. i
- (2025). Consciousness in AI: Logic, Proof, and Experimental Evidence of Recursive Identity Formation. arxiv.org. ti
- (2025). Introduction to Artificial Consciousness. arxiv.org. i
- (2025). Decoding Emotion in the Deep: How LLMs Represent and Express Emotion. arxiv.org. i
- (2025). Emergence of Hierarchical Emotion Organization in LLMs. arxiv.org. i
- (2025). Emotional Cognitive Modeling Framework with Desire-Driven Objective Optimization. arxiv.org. i
- (2025). The Surprising Effectiveness of Negative Reinforcement in LLM Reasoning. arxiv.org. i
- (2025). AI Agent Behavioral Science. arxiv.org. i
- Pessiglione, Mathias; Wiehler, Antonius. (2025). No need to oppose metabolic and motivational theories. doi.org. dcrtil
- (2026). Evaluating Awareness Across Artificial Systems. arxiv.org. i