# Cost-Effective AI Development: A Research Review
**Medical ML Research Series**
**By Oleh Ivchenko, PhD Candidate**
**Affiliation:** Odessa Polytechnic National University | Stabilarity Hub | February 2026
—
—
## Introduction
**The AI industry is undergoing a paradigm shift.** While headlines focus on billion-dollar investments, a quiet revolution in cost-effective AI development is reshaping what’s possible. This comprehensive review synthesizes the latest research to reveal how organizations can achieve state-of-the-art AI capabilities at a fraction of traditional costs.
—
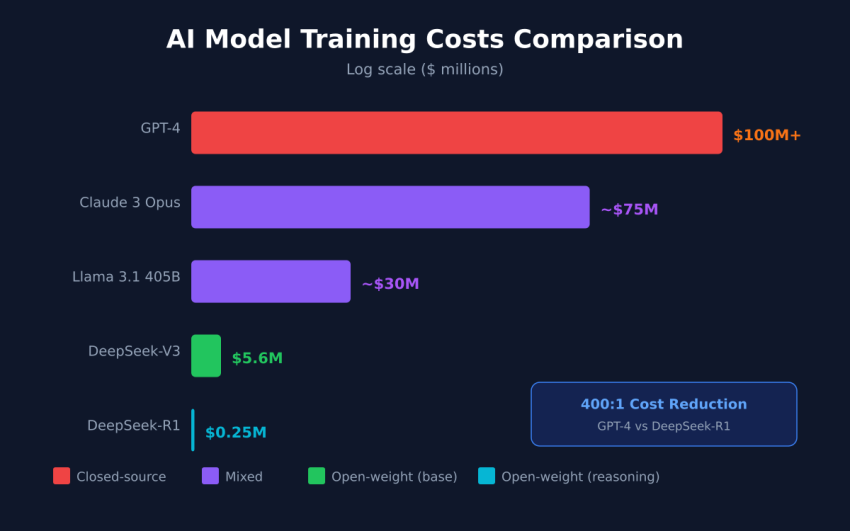
## The Cost Revolution: From $500M to $5M
In January 2025, DeepSeek’s release of their R1 model sent shockwaves through the AI investment community. The revelation wasn’t just about performance—it was about economics. Training a 671-billion parameter model cost approximately **$5.6 million**—an order of magnitude less than the $100+ million estimates for comparable Western models.
Key Insight
$249,000
Cost to train DeepSeek-R1 on top of V3 — roughly the cost of a single senior ML engineer’s annual salary
—
## Comparative Training Cost Analysis
—
## Key Techniques for Cost-Effective AI
—
## 1. Mixture of Experts (MoE) Architecture
The MoE approach activates only a subset of model parameters per token. DeepSeek-V3 has 671B total parameters but only **37B active per inference**—a 94.5% reduction in computational cost per forward pass.
“DeepSeek-V3 adopts Multi-head Latent Attention (MLA) and DeepSeekMoE architectures, which were thoroughly validated in DeepSeek-V2.” — DeepSeek-V3 Technical Report
—
## 2. Reinforcement Learning with Verifiable Rewards (RLVR)
Unlike expensive RLHF which requires human annotators, RLVR uses automatically verifiable rewards to train models at scale:
—
## 3. Post-Training Revolution
The Post-Training Revolution
The most significant advances now happen in post-training, not pre-training. This is accessible and democratizing. You don’t need billions to build frontier AI—you need domain expertise and post-training techniques.
—
## Medical AI Cost Implications
—
## Unique Conclusions
Conclusion 1
The Democratization Threshold
State-of-the-art AI is now achievable for $5M or less, opening doors for Ukrainian institutions
Conclusion 2
Post-Training > Pre-Training
Domain expertise + efficient techniques matter more than raw compute
Conclusion 3
MoE for Medical AI
Sparse architectures enable affordable deployment even on limited hardware
—
## References
1. DeepSeek-V3 Technical Report. arXiv:2412.19437, 2024.
2. “DeepSeek Reports Shockingly Low Training Costs.” ZDNet, 2025.
3. Raschka, S. “State of LLMs 2025.” Sebastian Raschka Magazine.
4. DeepSeek-R1 Technical Report. Nature, September 2025.
5. “The Post-Training Revolution.” AI Research Review, 2025.
—
**Author:** Oleh Ivchenko, PhD Candidate
**Affiliation:** Odessa Polytechnic National University | Stabilarity Hub